|
|
|
|
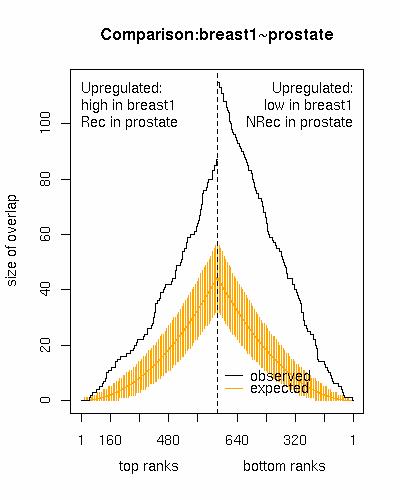
Similarities of Ordered Gene ListsClaudio Lottaz, Stefanie Scheid, Xinan Yang BackgroundIn microarray studies, researchers often compare gene expression profiles from two different conditions to generate lists of induced genes ordered according to a measure of up and down regulation. For comparing results generated in different studies, we can search for similarities between ordered gene lists. Potential applications include comparing independent microarray studies addressing the same research question to confirm findings. More interestingly, we can compare studies from slightly different but related contexts, for example survival in different types of cancer. Here gene list comparison can discover common markers. Comparisons are also feasible between different technological platforms, for instance between studies performed on different microarrays. Actually, data can also be deduced from heterogeneous data sources, for example protein activities measured with immunoprecipitation arrays, allele frequencies determined in SNP studies, or brain activity per voxel determined by functional magnetic resonance imaging (fMRI). Significance analysisWe define a similarity score to quantify list similarity. To compute the score, we determine the number of shared elements S_n in the first n elements of the lists for each n. The final score is a weighted sum over S_n where the ends of the lists receive larger weights, thus ensuring that the most strongly induced genes dominate the score. Randomly perturbed input data is used to estimate null distributions of this similarity score and empirical p-values provide a measure of significance for observed list similarities. ResultsA list comparison analysis yields a significance estimation for the observed similarity. In addition the method detects how far into the lists striking similarities occur. Finally, our algorithm determines the genes that drive the observed similarity score, that is genes with prominent ranks in all compared lists. These genes are most promising for further analysis and interpretation. We have analyzed various leukemia microarray datasets comparatively for the NGFN Acute Leukemia Consortium.
SoftwareTry the suggested method using our Bioconductor compliant R package--> Publications, talks and posters
|
|||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||